
Destinée à un public expert, voici une description de l’agent ReActEngine Mistral v104 fondé sur llama_index.core.agent.workflow.ReActAgent, intégrant Finalizer, ToolRouter, RAG, outils personnalisés et orchestration.
ReActEngine Mistral v104 — Description technique
1. Nature de l’agent
L’agent Mistral ReAct v104 est un moteur agentique basé sur le paradigme ReAct (Reasoning + Acting).
Il combine :
-
un LLM Mistral (via API ou local),
-
un orchestrateur d’outils dont MCP,
-
un Finalizer pour la génération contrôlée,
-
un ToolRouter pour la sélection dynamique d’outils,
-
un RAG (Research Augmented Generation) modulaire basé sur l’agent de recherche Chat Engine Mistral utilisé par notre ChatBot simple.
Il s’appuie sur la classe ReActAgent(Workflow) plutôt que sur les agents préconstruits, afin de garantir :
-
un contrôle fin du cycle ReAct,
-
une meilleure auditabilité,
-
une intégration propre des outils personnalisés,
-
une compatibilité avec les pipelines agentiques complexes.
Constatant que les erreurs dans la boucle ReAct non interceptées ou mal traitées aboutissaient sur un arrêt intempestif et silencieux du raisonnement, un principe est posé : dans la boucle ReAct, seules deux exceptions peuvent ( et doivent ) être levées : RetryException et ForceFinalizeException. Le message d’erreur doit être explicite pour permettre au raisonnement de poursuivre ou de retourner proprement vers l’utilisateur. Ceci a motivé une part des modifications au code de Llamaindex.
Avec le même objectif - éviter les arrêts du raisonnement - deux autres modifications portent sur la génération et le traitement de question posée à l’utilisateur ainsi que le recours au RAG pour y trouver des informations susceptibles de guider le raisonnement.
Points clés de la version v104
-
Intégration du Finalizer (contrôle de la réponse finale).
-
Intégration du ToolRouter (sélection dynamique des outils).
-
Utilisation de
ReActAgent(Workflow)plutôt que l’agent préconstruit, afin d’atteindre le cœur de la boucle ReAct et y apporter des améliorations . -
Accès du LLM au RAG avec l’outil
RagTool. -
Accès du LLM aux données temps réel avec MCP.
-
Architecture stateless côté agent, stateful côté application.
-
Gestion centralisée des erreurs assurant la continuité du raisonnement.
2. Architecture générale
2.1. Diagramme des échanges
Les modules de la partie gauche (ReActEngine, ToolRouter, ReActFinalizer, ReActStreamParser) ont été développés spécialement pour atteindre les objectifs du ReActEngine v1, tandis que la partie droite comprend les modules du ReActAgent(Workflow) de LlamaIndex avec quelques adaptations. Le LLM est une API de MistralAI.
Conseils : Cliquez sur le diagramme pour le zoomer. Ouvrez le diagramme dans une autre fenêtre pour mieux suivre la suite.
2.2. Vision globale du flux
-
Utilisateur → ReActEngine : prompt.
-
ReActEngine → ToolRouter : sélection d’outils.
-
ReActEngine → ReActAgent : initialisation du pipeline.
-
Formatter → LLM : message formaté.
-
LLM → StreamParser : tokens bruts → blocs ReAct.
-
Parser → Agent : StepResult.
-
Workflow : décide de la suite (outil, raisonnement, final).
-
Finalizer : rebouclage sur erreur ou réponse finale.
-
ReActEngine → Utilisateur : streaming de la réponse.
A partir d’ici, nous pouvons distinguer :
-
La boucle ReAct reposant sur les modules LlamaIndex : ReActAgent, BaseWorkflowAgent, ReActWorkflow, ReActOutputParser. Seule la boucle ReAct échange avec le LLM.
-
L’Orchestrateur composé des modules de haut-niveau : ReActEngine, ToolRouter, ReActFinalizer, ReActStreamParser. ReActAgent est le seul lien avec ce niveau applicatif.
2.3. Boucle ReAct
L’agent suit la logique décrite dans Synergizing Reasoning and Acting in Language Models :
-
Reasoning : le LLM produit une intention ou un plan.
-
Acting : l’agent appelle un outil.
-
Observation : l’outil renvoie un résultat.
-
Reasoning : le LLM intègre l’observation.
-
Final Answer : produit par le Finalizer.
Avec LlamaIndex ReActAgent basé sur Workflow, la boucle ReAct est orchestrée par répétition de la fonction take_step(). Toute action est synonyme d’appel à un outil. Il est mis fin à la boucle lorsqu’une réponse finale est détectée .
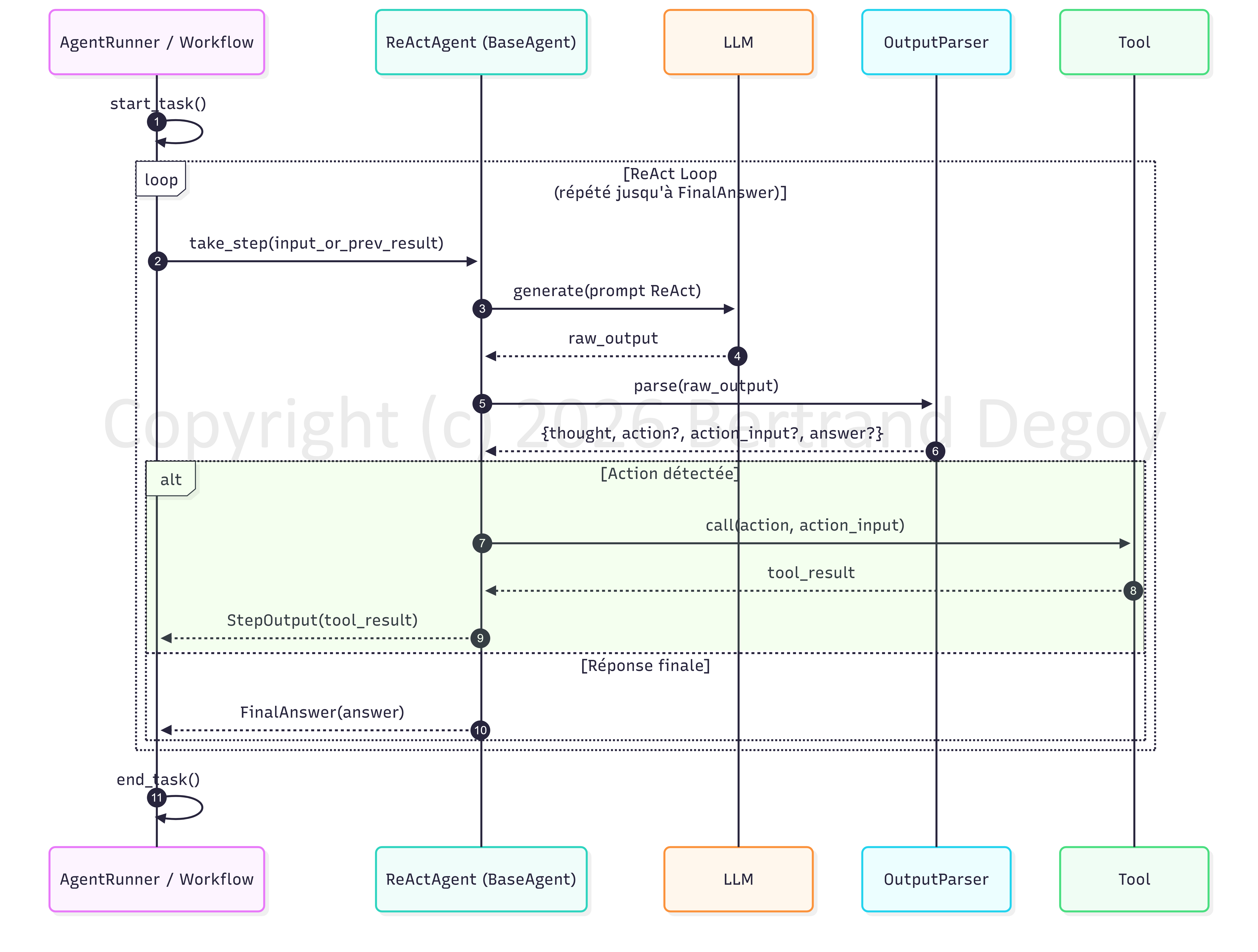
En résumé :
-
Le workflow ne fait qu’appeler en boucle la méthode take_step.
-
ReActAgent construit chaque étape en appelant le LLM.
-
Le parser transforme les deltas en blocs ReAct.
-
Le finalizer décide si l’agent doit continuer ou s’arrêter.
-
Le workflow relance l’étape tant que nécessaire.
ReActAgent (remanié)
Entrée : message formaté (prompt + contexte + outils).
Traitement :
Implémente la logique ReAct :
Thought → Action → Observation → Thought → …
Décide quand appeler un outil.
Produit un StepResult à chaque itération.
Sortie : StepResult (structure contenant Thought/Action/Observation).
Ce module est au centre du protocole ReAct. Il fournit l’infrastructure nécessaire pour traiter : la construction des étapes de raisonnement, les appels au LLM, le parsing structuré des réponses du LLM, le déclenchement d’outils, la production de la réponse finale.
Le ReActAgent ne traite qu’une étape à la fois. Il est appelé, d’étape en étape, par la méthode run_agent_step du Workflow.
La méthode take_step()
Au cœur de la boucle ReAct, cette méthode traite une seule étape de raisonnement :
-
Formater l’entrée du LLM à l’aide du template ReAct.
-
Appeler le LLM (en mode streaming ou non).
-
Parser la sortie du modèle en un ReasoningStep structuré.
-
Gérer les erreurs de parsing ou les états ReAct invalides.
-
Puis, selon le cas :
-
retourner une réponse finale,
-
déclencher un appel d’outil,
-
ou demander au LLM de réessayer ou de finaliser.
-
Les principales modifications portent sur la gestion des sorties LLM mal formées ou incomplètes, ainsi que sur le traitement des exceptions :
-
normalisation du format de sortie du LLM, contribuant à rendre l’agent agnostique en ce qui concerne les LLMs dont les formats sont peu normalisés.
-
relance de la boucle lorsque le parseur détecte une sortie ReAct incomplète, mal formée ou autrement invalide, mais pouvant être corrigée par le modèle.
-
traitement de deux exceptions, :
-
RetryException→ la sortie est incomplète ou tronquée ; le LLM doit réessayer en se fondant sur le message d’erreur. Cela couvre aussi les erreurs des outils. -
ForceFinalizeException→ le modèle a produit un état ReAct invalide (ex. : Thought sans Action ni Answer) ; le prochain appel LLM doit produire uniquement une réponse finale. Ces exceptions sont les seules autorisées au sein de la boucle afin d’éviter les arrêts silencieux de l’agent. Toutes les exceptions d’une autre classe levées au sein du code sont interceptées et ramenées à l’une de ces deux exceptions.
-
La méthode handle_tool_call_result()
Cette méthode traite les résultats des appels d’outils :
-
récupère l’historique courant de raisonnement (variable d'état ctx),
-
inspecte chaque résultat d’outil,
-
distingue les erreurs réelles des contenus vides légitimes,
-
normalise le contenu observé,
-
ajoute une étape d’observation au raisonnement,
-
gère les cas particuliers (ask_user, return_direct),
-
met à jour l’état persistant du raisonnement dans le contexte (variable d'état ctx). Les principales modifications incluent :
-
la distinction entre un retour d’outil légitimement vide et une erreur de l’outil.
-
la normalisation du retour d’outil (le contenu observé), contribuant à l’adaptation aux différents LLMs.
-
une détection d’erreurs garantissant que les outils signalent explicitement leurs échecs en levant l’une des exception RetryException ou ForceFinalizeException afin d’éviter un arrêt intempestif du raisonnement.
-
la gestion d’un outil AskUserTool ( créé dans la GeneralToolBox ) permettant au modèle de poser une question à l’utilisateur, puis la transformation de sa réponse en Observation ReAct et la relance de la boucle ReAct via take_step().
BaseWorkflowAgent (modifié)
Entrée : StepResult ou message intermédiaire.
Traitement :
Gère la logique générique d’un agent (état, transitions, erreurs).
Coordonne les appels entre Workflow, Formatter, Parser.
Sortie : instructions pour la prochaine étape du workflow.
La principale modification porte sur la gestion de la pause en attente d’une réponse de l’utilisateur (outil AskUser).
ReActWorkflow
Entrée : StepResult + contexte d’exécution.
Traitement :
Orchestration du cycle ReAct.
Détermine si l’agent doit :
continuer à raisonner,
appeler un outil,
ou produire la réponse finale.
Sortie : nouvelle étape à exécuter (run_step).
ReActChatFormatter
Entrée : prompt utilisateur + état du workflow.
Traitement :
Formate le message dans le style attendu par le LLM (system + user + tool instructions).
Injecte les outils dans le prompt si nécessaire.
Sortie : message formaté envoyé au LLM.
ReActOutputParser (modifié)
Entrée : sortie brute du LLM.
Traitement :
Analyse la réponse du LLM.
Extrait Thought / Action / Observation / FinalAnswer.
Détecte les erreurs de format.
Sortie : StepResult structuré.
Les principales modifications portent sur une détection et une gestion correcte des erreurs en levant RetryException ou ForceFinalizeException afin d’éviter les arrêts intempestifs du LLM.
Modèle LLM
Entrée : message formaté (prompt complet).
Traitement :
Génération token-par-token.
Produit du texte brut sans structure interne explicite.
Sortie : tokens bruts → envoyés au StreamParser.
Il faut noter que, si de nombreuses adaptations visent à rendre notre ReActAgent agnostique vis-à-vis des LLMs, notamment en normalisant les formats des requêtes et des réponses, cela n’est pas encore finalisé dans l’état actuel du développement.
Tool
L’agent combine trois familles d’outils :
A. RAG (QueryEngineTool)
-
Basé sur
chat_engine_mistral_v1.3.x. -
Utilise les index créés par RAG Manager ou IngestCmd.
-
Permet un RAG cohérent, multithème, multilingue.
Exposer un outil RAG à la boucle ReAct permet au LLM d’accéder à des descriptions systémiques, des routines de raisonnement, des spécifications etc., tout documents normatifs permettant de soutenir le raisonnement et de le ré-orienter en cas d’impasse.
B. Outils personnalisés (FunctionTools)
-
Fournissent des données temps réel (par exemple issues de WhatisWhat).
-
Les données sont injectées via MCP. Voir : ReAct et intégration des données temps réel avec MCP ( Model Context Protocol )
-
Exemples : météo, état d’un système, données métier, etc.
Voir également : RAG : Chat Engine ReAct avec outils
C. Outils généralistes
-
Calculs : arithmétique, statistique
-
Manipulation de texte
-
Utilitaires divers
2.3. Orchestrateur
De ce point de vue, on peut considérer le ReActEngine décrit précédemment comme une boîte noire (dont on représente tout de même l’essentiel pour une meilleure compréhension) animée par l’Orchestrateur.
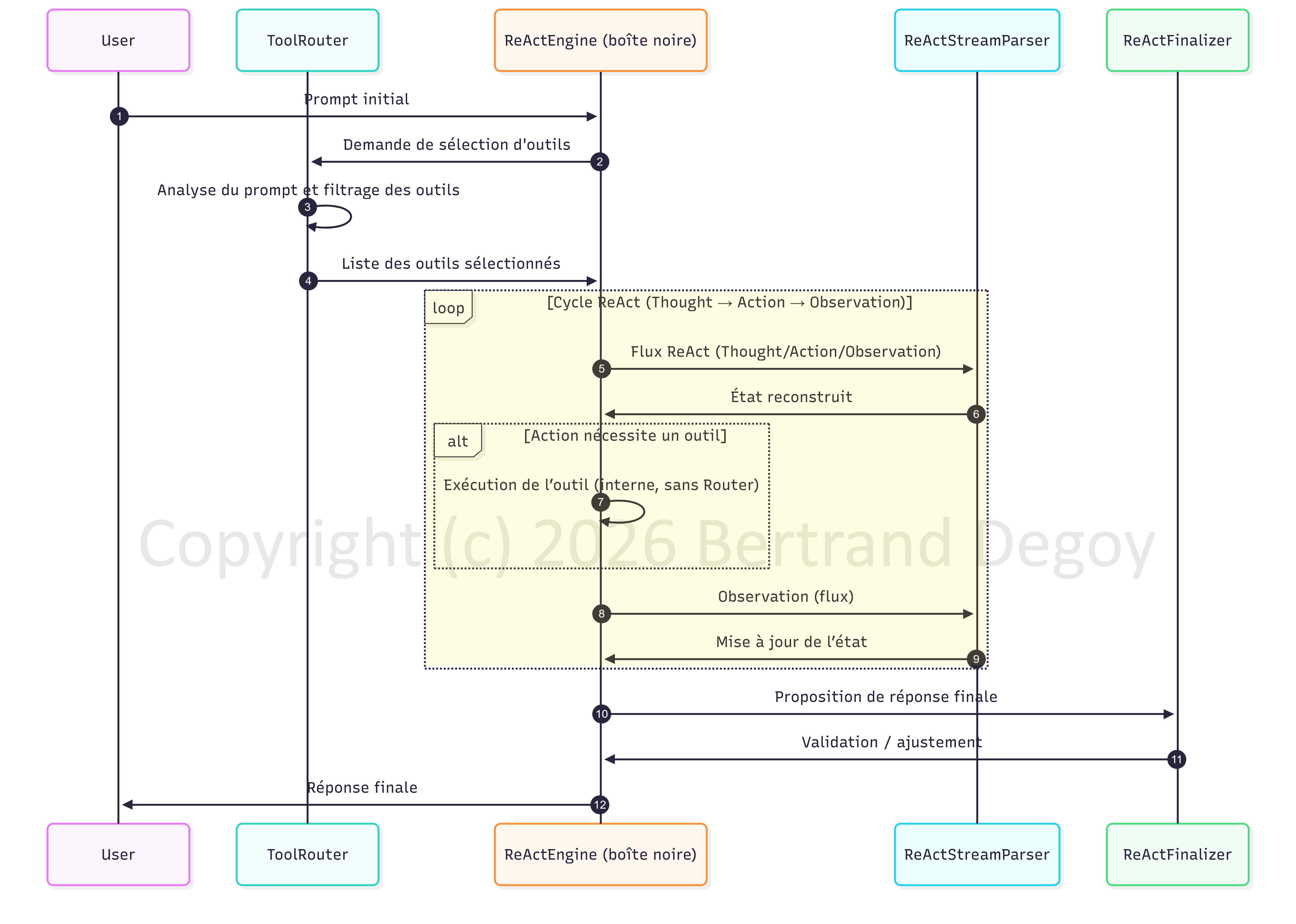
User
Entrée : intention humaine, question, commande.
Traitement : aucun — c’est la source du prompt.
Sortie : prompt utilisateur envoyé au ReActEngine.
ToolRouter
Entrée : prompt brut.
Traitement :
Analyse sémantique du prompt.
Sélectionne les outils pertinents (toolbag).
Sortie : liste d’outils pertinents → renvoyée au ReActEngine.
ReActEngine
Entrée : prompt utilisateur.
Traitement :
Détermine si le prompt nécessite des outils.
Appelle le ToolRouter pour identifier les outils pertinents.
Initialise un agent ReAct complet (Finalizer, Workflow, Formatter, Parser…).
Lance la boucle de streaming (token-par-token).
Sortie : flux de tokens structurés (Thought / Action / Observation / FinalAnswer).
ReActStreamParser
Entrée : tokens bruts provenant du LLM.
Traitement :
Reconstitue les blocs ReAct (Thought, Action, Observation…).
Filtre les artefacts, nettoie les tokens.
Émet des fragments de réponse via un générateur asynchrone.
Sortie : tokens nettoyés + blocs ReAct structurés.
ReActFinalizer
Entrée : instance d’agent ReAct.
Traitement :
Surveille la fin du raisonnement.
Détecte un FinalAnswer ou une condition d’arrêt.
Nettoie et finalise la réponse.
Sortie : réponse finale propre, prête à être envoyée à l’utilisateur.
3. API du ReActEngine v1
3.1. __init__(...)
Deux modes d’initialisation :
Mode 1 : avec ragkwargs
-
Adapté à une utilisation en mode API, relançant l’instanciation à chaque requête.
-
Le thème, la langue, le niveau de détail, etc. sont fournis dès l’instanciation.
-
L’agent est immédiatement opérationnel.
Mode 2 : sans ragkwargs
-
Adapté à un fonctionnement en mode daemon ou worker multi-thèmes.
-
L’application doit ensuite appeler
start()avec le thème en argument.
Paramètres clés :
-
config: configuration globale (commune à IngestCmd, ChattyBot, ChattyWS…) -
llmapikey: clé API MistralAI -
token: jeton de sécurité pour les serveurs de données -
ragkwargs: dictionnaire contenant au minimum :-
theme -
detail -
language
-
3.2. Méthode start()
Méthode pour les services REST ou workers persistants.
-
complète l’initialisation selon le thème,
-
charge l’index si nécessaire,
-
permet aux applications stateful de fournir leur propre index (optimisation),
-
prépare l’agent ReAct pour le thème courant.
Retour : un objet ReActAgent prêt à l’emploi.
3.3. Gestion de l’historique — set_history()
Cette méthode :
-
reçoit un historique OpenAI-style :
[{ "role": "user", "content": "..." }, ...] -
nettoie et compresse l’historique pour compatibilité ReAct,
-
stocke :
-
self.conversation_history -
self.compressed_history
-
L’agent est statique :
→ l’application appelante doit gérer la persistance de l’historique ( plus précisément "historique de conversation" ) et le transmettre avant chaque requête.
3.4. Exécution asynchrone — stream(prompt)
Fonctionnement
Pour chaque prompt :
-
ToolRouter sélectionne dynamiquement les outils pertinents
→ réduction du contexte, optimisation des coûts, meilleure précision. -
L’agent ReAct est reconstruit avec uniquement les outils routés.
-
Un tote bag est préparé :
-
historique compressé
-
langue
-
profil (ex. "expert")
-
-
Le ReActFinalizer gère la génération incrémentale.
-
La méthode retourne un AsyncGenerator.
3.5. Exécution synchrone — get_engine_response()
Fonctionnement
-
récupère l’historique compressé si non fourni,
-
applique le ToolRouter,
-
exécute l’agent ReAct,
-
retourne une réponse complète (non streamée).
4. Mise en œuvre des outils dans ReActAgent
4.1. Les outils
L’agent s’appuie sur trois ToolKits complémentaires :
-
GeneralToolKit : outils génériques toujours disponibles.
-
ThemeToolKit : outils métier + un outil RAG pour accéder à la documentation interne.
-
ToolKit Temps Réel : outils connectés à des sources de données dynamiques (internes/externes).
Voir également : ReAct et intégration des données temps réel avec MCP ( Model Context Protocol )
4.2. L’outil RAG dans la boucle ReAct
Le RAG (Research Augmented Generation) est intégré comme un outil standard, accessible via la logique ReAct.
Rôle du RAG
Il permet à l’agent d’interroger la documentation interne de l’entreprise, composée de : documents historiques (rapports, notes, logs), référentiels documentaires (procédures, notices techniques), routines spécialisées pour guider le raisonnement dans des tâches répétitives.
Fonction dans ReAct
Le RAG est utilisé lorsque l’agent doit : vérifier une information interne, s’appuyer sur des documents de référence, exécuter une tâche nécessitant un contexte métier documenté.
Le RAG enrichit le raisonnement de l’agent en lui donnant accès à la connaissance interne, tout en restant orchestré par ReAct.
4.3. le ToolRouter
Le ToolRouter identifie automatiquement les outils les plus adaptés à une requête utilisateur grâce à un mécanisme de similarité vectorielle.
Fonctionnement : Chaque outil possède une description textuelle (métadonnées). Voir : ReAct : la carte des intentions : Intent Map Les descriptions et la requête utilisateur sont vectorisées via un modèle d’embedding. Le routeur calcule la similarité cosinus entre la requête et chaque outil. Les outils sont classés par pertinence. Le ReActAgent choisit l’outil à appeler en fonction du classement et du contexte.
Résultat : Un agent capable de combiner raisonnement, outils spécialisés, documentation interne et données temps réel.
